前言:
这几天,又去肯德基打工了。当初说好不去的,可是家里饭太难吃,索性就当去吃员工餐了。前几天看到群里有人在说一个很屌的云盘搜索,整个程序30MB,功能非常完善,包括分享之类的模块,用户统计,主动采集等。这样的完不了,那么就玩点简单的,项目命名“百老王搜索”。
鸣谢 三弟土狗 大哥柴犬君 Ranger 的帮助和指导。

进行过程:
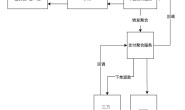
首先我们需要弄清楚这个云盘搜索是怎么回事,其实很简单,用的是 site:pan.baidu.com 关键词 的方法,在百度或者其他搜索引擎直接采集搜索引擎目录结果。我们先做个试验。如下图,其实这尼玛就是SEO经常用到的,相关页面检索而已。

程序规划:
原来的计划准备采集日本驻波大学的GVPN计划页面,加上一个云盘搜索然后发布,但是最后想了想,现在云盘搜索SEO都干不过别人,权当练手了,就没有发布计划,GVPN采集涉及到数据库直接放弃了,这尼玛是浪费时间。
后台使用request模块进行采集,使用URL模块进行URL分析,cheerio对网页元素进行筛选。
计划执行
app.js包含路由:
app.use('/',routes);
app.use('/data/search',Rseach);
route.js(index)
var express = require('express');
var router = express.Router();
router.get('/', function(req, res, next) {
res.render('index', { title: '百老王' });
});
module.exports = router;
search.js(搜索处理)
var request=require('request');
var Cheerio=require('cheerio');
var Entitles=require('html-entities').XmlEntities;
//entitile模块代码下有注释
var Url=require('url');
function Search (re){
this.key = re.key;
this.page=re.page
};
module.exports=Search;
Search.prototype.find=function(callback) {
var key = {
key:this.key,
page:this.page
};
var queryq = {
url:'http://cn.bing.com/search?q='+'site:pan.baidu.com '+key.key+'&first='+this.page,
headers:{
'cookie':'SRCHUID=V=2&GUID=0DC3F004C1024FAD89E7B909A82F22E0; MUIDB=35C4A1466BBF638F32ABA92F6FBF6267; MUID=35C4A1466BBF638F32ABA92F6FBF6267; SRCHD=AF=IESS02; SRCHUSR=AUTOREDIR=0&GEOVAR=&DOB=20151230; SRCHHPGUSR=CW=1519&CH=324&DPR=1.25&NEWWND=1&NRSLT=50&AS=1&NNT=1&HIS=1&HAP=0; ANON=A=6EF56BD3E3B71549C914CBE4FFFFFFFF&E=11d1&W=1; NAP=V=1.9&E=1177&C=p7DKDOI-Jfg5OBpD-xBgpzLpuroFLO0-2BuLkPOXw8_K-akpdgqrHQ&W=1; _SS=SID=0650419DF5946E5F2DF1493AF4866F46&bIm=99348%3a&HV=1453690792&PC=EUPP_; _EDGE_S=mkt=zh-cn&SID=102475C36F8169A223817D646E206833; _UR=D=0; SCRHDN=ASD=0&DURL=#; KievRPSAuth=FAA6ARRaTOJILtFsMkpLVWSG6AN6C/svRwNmAAAEgAAACNJhQUs0oT/j%2BABnFy5OYGxv6%2BKJqUTDLJtDTcvNXtnMrh8I32uhzIlOHH7v7fj9rMdjK/TJSeF%2BAFarx32EXLH0m0O0t8onfxfrZctS01lVM4qLhCWmZCn1bJgw6iuvt1L7/X3rhWkD7xL0jlnc8HwqHKZwtsp0GOf3YkPQSAhqDh6nJbgNEG63E9A2Cr418TH0PLgipcvSjUYv1dqeIyNHUoeYuOH03j2ioZNqy2Z1Uonkkn0N7ifjJPacLONRcB/UDCp3dN0M9s0MeFq/zPTg8/sdycjT0/I0gSPnPE1d14G12ksK1YuzA3GtXzxl%2Bvhzz69wPPzzf9/5lJ0bKhKKUhQArIFdkAN3y/EKG2KHd0FlgtNLYnE%3D; PPLState=1; _U=13Jtf184vqrnZHnTCh6Jk_iGYb35aenhGeC8fkNZ8d9ri6RAGoIoZdGgq71ATfrrIICwgvu3ApcCwhZdiSQy8oUxVjN6YWOZ2unyCLjV1G_Y; WLS=C=9e493b5505188972&N=ge; WLID=gvZ5Luand4hgDnnHPrV/lvxy8OA20rjbCLXrO2zszR9A6gPLqCySsELTp/NIRi0Gu5bEYL+tQA8eqsfMktdUZXvhpM6axklauUUXpWESDKA=; _FP=hta=on; SRCHS=PC=EUPP_'
}
};
var classList=[];
request.get(queryq,function(error,response,body){
var $=Cheerio.load(body);
var entitles=new Entitles;
$('.b_algo','#b_results').each(function () {
var $me = $(this);
var name = entitles.decode($me.find('h2>a').html());
var url = Url.parse($me.find('h2>a').attr('href')).href;
var message = $me.find('div>p').text();
var item={
name:name,
url:url,
message:message
}
if (item.url!="http://pan.baidu.com/error/404.html"){
classList.push(item);
}else {
if(classList=[]){
var err={
};
return callback(null,err);
}
}
})
return callback(null,classList);
});
}
你可能看到headers的cookie里有一段很长的cookie值,这是哪来的呢?默认访问必应的时候,每页显示10条记录,这对我们来说是不够的,好在左上角的设置里有一个每页条目,我直接改成了50,在没登录的情况下,清除cookie后发现又回到10条,如此想来如果服务器没有定时销毁SESSION的话,而且没有登录就能设置,想起来使用习惯应该不会销毁SESSION可能仅仅是一个简单的cookie在头里面发挥作用,于是我索性用httpwatch看了下request发送的headers头,然后直接赋值给nodejs的request模块,果然不出所料,直接显示50条,而且2天也没有消除。
接下来,由于搜索引擎使用<strong>标签环绕关键词,如果cheerio使用.text的话会忽略这个标记,而且给程序加大了难度,所以我使用.html方法,但是发现转码后<strong>标记虽然保留,但是出现了utf8汉字转化的一堆码,是Unicode无异,但是不知道具体是什么。使用iconv模块转utf和gbk均无法还原,这个东西原来叫:“html-entities”html实体。这都记下吧,别以后闹笑话。
翻页带入page=?,使用GET方法,亲测可用。前端没有翻页,手动翻翻看,反正不准备发布。过滤404百度云条目不进行检索。
至此我们的package包含了以下模块。当然express组件就没写。
"request":"*", "cheerio":"*", "html-entities":"*", "url":"*"
rsearch.js(show页面)
var express = require('express');
var router = express.Router();
var Search=require('../module/search');
router.get('/', function(req, res, next) {
var idea =new Search({
//key为中文,亲测需要进行URL编码,否则会出现乱码的情况
key:encodeURI(req.query.guanjianci ),
page:req.query.page
});
console.log(req.query.page);
idea.find(function(err,reldata){
res.render('show',{
title: req.query.guanjianci,
data:reldata
});
});
});
module.exports = router;
jade渲染
for item in data
div.cell.debug
a(href=item.url)
!{item.name}
br
!{item.message}
jade的缩进我也是醉了,看着整吧,醉了醉了。前端交给三弟土狗来给弄的,ps:干了一半不干了。大家不能和这种禽兽为友。还好发现有html转jade的在线转换,百度一个国外网站,轻松就转出来了。话说jade对于新手实在是太反人类了。
全文结束:
这次记录主要是讲了一个采集遇到的比较常见的问题,话说cheerio实在是太强大。这个案例很简单,主要是记录下蛋疼的错误点。